
The monumental task of training large-scale artificial intelligence models has evolved into a high-stakes orchestration of immense computational power, where the difference between a groundbreaking discovery and a costly failure hinges on mastering the complex dance of distributed GPU clusters. As models grow exponentially in size and capability, the underlying infrastructure required to build them has become a critical battleground. Successfully navigating this landscape of multi-node, high-performance computing is no longer an advantage but a fundamental requirement for any organization aiming to operate at the frontier of AI development. This challenge is not merely about acquiring hardware; it is about unlocking its full potential through meticulous engineering, precise configuration, and a deep understanding of the bottlenecks that can silently sabotage even the most ambitious projects.
The Multi-Billion Dollar Question: What Separates a Breakthrough AI Model From a Computational Dead End
The chasm between owning a fleet of powerful GPUs and successfully training a state-of-the-art model is vast and littered with failed projects that underestimated the complexity of distributed systems. The core issue lies in orchestrating these individual accelerators to function as a single, cohesive supercomputer. Without a harmonized approach, a cluster of hundreds of GPUs can perform worse than a much smaller, well-configured system, leading to staggering financial losses from wasted compute cycles and extended development timelines.
This reality has shifted the focus from raw computational power to the science of system efficiency. The most advanced AI labs now recognize that their competitive edge is defined not just by their algorithms but by their ability to scale training workloads seamlessly across thousands of processors. Solving this multi-billion dollar question requires a blueprint for building and validating high-performance infrastructure, ensuring that every expensive GPU is contributing its maximum potential toward the final goal. The alternative is a computational dead end, where progress stalls, and resources are squandered.
Why Your Single Server Can’t Handle the AI Revolution
The first insurmountable obstacle for large models is the memory wall. A 70-billion-parameter model, even when using mixed-precision formats, demands between 400 and 600 gigabytes of memory for its weights, optimizer states, and activation gradients. This figure far exceeds the capacity of any single GPU server on the market, making it physically impossible to contain the model within one machine. The era of single-node training for frontier models is definitively over, necessitating a distributed architecture where the model itself is partitioned across numerous interconnected nodes.
Beyond memory constraints, the speed imperative dictates the use of multi-node clusters. While it might be theoretically possible to train a model over an excruciatingly long period on a smaller system, the competitive nature of AI development renders this approach obsolete. A properly configured 128-GPU cluster can achieve a 12 to 15-fold speedup compared to an 8-GPU system, transforming training timelines from months into a matter of days. This acceleration is crucial for rapid iteration, experimentation, and ultimately, for delivering a model to market in a relevant timeframe.
However, simply connecting more GPUs is not a guarantee of performance. The hidden bottleneck in most large-scale training setups is the network. Inter-GPU communication is constant and intensive, as gradients and activations must be synchronized across the entire cluster. A poorly configured or undersized network can cripple performance, causing GPUs to sit idle while waiting for data. This can slash effective GPU utilization to as low as 40%, meaning more than half of the investment in computational hardware is being wasted at any given moment.
Inside the Machine: A Real-World Look at Training a 72B Model
In a production environment designed for cutting-edge models, the hardware configuration is both massive and intricate. A successful deployment for a 72-billion-parameter model, for instance, involved a cluster of 16 dedicated nodes, each equipped with 8 B300 GPUs, for a total of 128 accelerators working in concert. To manage the immense workload, a hybrid parallelism strategy was employed. Tensor Parallelism (TP=8) split individual model layers across the 8 GPUs within each node, while Pipeline Parallelism (PP=2) assigned different sets of layers to different groups of nodes, creating a computational assembly line that maximized throughput.
The performance metrics from such a setup underscore the power of a well-tuned system. The cluster consistently achieved 45-50% Model Flops Utilization (MFU), a key indicator of computational efficiency. This was supported by an aggregate inter-node bandwidth of 6.4 terabytes per second facilitated by InfiniBand RDMA, enabling rapid synchronization. The resulting throughput reached approximately 2,500 tokens per second for each of the 128 GPUs, demonstrating a high level of sustained performance. To ensure stability, checkpoints were saved to distributed storage every 500 steps, mitigating data loss from inevitable hardware failures.
Even in a finely tuned environment, teams must anticipate and manage common failure modes. The complexity of a 128-GPU system means that hardware issues are a statistical certainty. Frequent problems include PCIe bus errors that can cause an entire node to become unresponsive, as well as intermittent NVLink connectivity failures between GPUs that require targeted resets. Robust fault tolerance software and diligent monitoring are therefore essential components for ensuring that a training run can survive these events and proceed without catastrophic data loss or corruption.
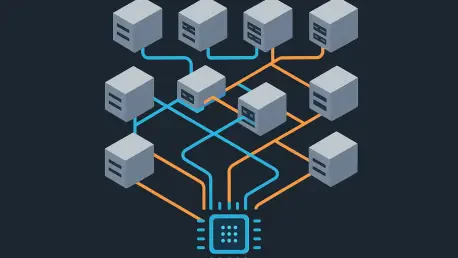
The Anatomy of a High-Performance AI Cluster
The circulatory system of a modern AI supercomputer is its multi-layered network fabric. Within each server node, communication is handled by ultra-high-speed NVLink interconnects, which provide a staggering 900 GB/s of bandwidth directly between the GPUs. This internal highway is essential for operations like tensor parallelism, where parts of a single matrix multiplication are spread across multiple GPUs. In contrast, communication between nodes relies on a different technology, typically InfiniBand or RoCE, which offers 400-800 Gb/s of bandwidth. This external network is the backbone for synchronizing the entire cluster and is critical for pipeline and data parallelism.
The interplay between these two network tiers is where performance is won or lost. As one expert noted, “Every percentage point of network overhead translates directly to lost GPU utilization.” This statement highlights the critical importance of minimizing latency and maximizing throughput at every step. If the inter-node network cannot keep pace with the intra-node computations, the GPUs will be forced into idle states, effectively burning through budget and time. Optimizing this data flow is a complex but non-negotiable task for achieving high efficiency in large-scale training.
The strategic importance of this specialized infrastructure is reflected in explosive market growth and targeted corporate investments. The global market for AI data center GPUs is projected to reach $197.55 billion by 2030, a clear signal of the industry’s commitment to large-scale computation. Furthermore, major players like NVIDIA continue to innovate in this space, with recent announcements of technologies like the BlueField-4 DPU aimed at creating AI-native storage and networking infrastructure. These developments validate the principle that the software, the hardware, and the network must evolve together to power the next wave of AI.
A Step-by-Step Guide to Scaling Your Own Models
Embarking on a full-scale training run without rigorous preliminary testing is a recipe for disaster. The most effective strategy is the “start small” philosophy, which involves methodically verifying the performance of the cluster at incremental scales. This approach allows teams to identify and resolve critical bottlenecks in networking, storage, or software configuration early on, before they can derail a multi-week training job and consume an enormous budget. Proactive validation is the foundation of efficient and predictable model training.
Before launching any workload, a pre-flight checklist is essential. The first step is to validate intra-node bandwidth using tools like nvidia-smi to confirm that all GPUs within a node are communicating at their expected NVLink speed. Next, inter-node throughput must be tested with utilities such as ib_write_bw to ensure the InfiniBand or Ethernet fabric is performing correctly. Finally, teams should conduct scaling tests, running a small version of the model on 2, 4, 8, and then 16 nodes. This progressive scaling helps pinpoint at what stage communication overhead begins to degrade performance, allowing for targeted optimization.
The successful launch of a large-scale training run depended on meeting specific performance benchmarks during these validation phases. The goal for intra-node communication was to achieve over 800 GB/s on NVLink, while inter-node bandwidth needed to reach at least 80% of the theoretical maximum for the InfiniBand fabric. Ultimately, the overall GPU utilization during these small-scale tests had to exceed 70% before the full budget was committed. It was this disciplined, step-by-step process of verification that transformed a complex collection of hardware into a reliable and efficient AI supercomputer, proving that meticulous engineering was the true key to unlocking its potential.